International Conference on Machine Learning (ICML) 2024
Make-A-Shape
A Ten-Million-scale 3D Shape Model
Zhengzhe Liu
The Chinese University of Hong Kong
Chi-Wing Fu
The Chinese University of Hong Kong
*Ka-Hei Hui and Aditya Sanghi are joint first authors.
 Our shape model, known as Make-A-Shape, has been trained on 10 million diverse 3D shapes. It exhibits the capability to unconditionally generate a wide range of 3D shapes, featuring intricate geometric details, plausible structures, nontrivial topologies, and clean surfaces, as demonstrated above. |
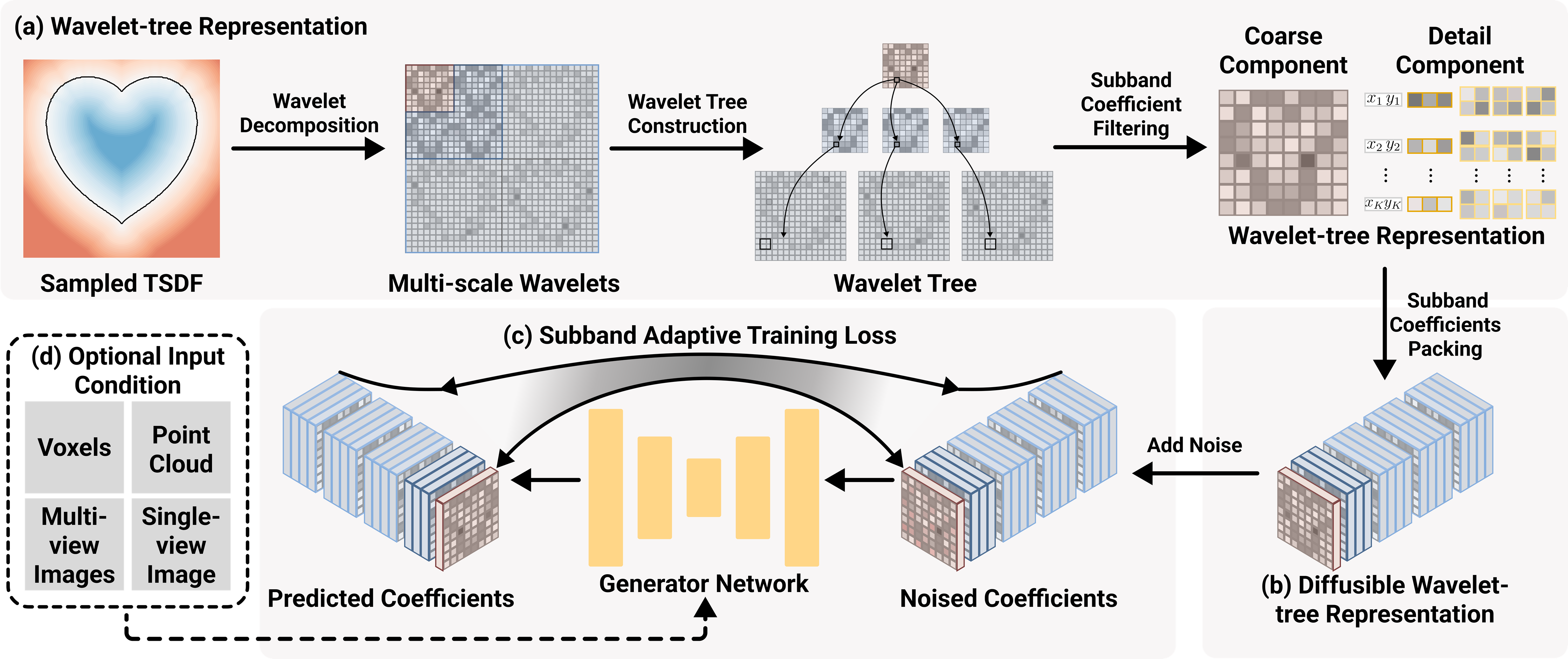 Figure 4. Overview of our generative approach. (a) A shape is first encoded into a truncated signed distance field (TSDF), then decomposed into multi-scale wavelet coefficients in a wavelet-tree structure. We design the subband coefficient filtering procedure to exploit the relations among coefficients and extract information-rich coefficients to build our wavelet-tree representation. (b) We propose the subband coefficient packing scheme to rearrange our wavelet-tree representation into a regular grid structure of manageable spatial resolution, so that we can adopt a denoising diffusion model to effectively generate the representation. (c) Further, we formulate the subband adaptive training strategy to effectively balance the shape information in different subbands and address the detail coefficient sparsity. Hence, we can efficiently train our model on millions of 3D shapes. (d) Our framework can be extended to condition on various modalities. |
Abstract
Significant progress has been made in training large generative models for natural language and images. Yet, the advancement of 3D generative models is hindered by their substantial resource demands for training, along with inefficient, non-compact, and less expressive representations. This paper introduces Make-A-Shape, a new 3D generative model designed for efficient training on a vast scale, capable of utilizing 10 millions publicly-available shapes. Technical-wise, we first innovate a wavelet-tree representation to compactly encode shapes by formulating the subband coefficient filtering scheme to efficiently exploit coefficient relations. We then make the representation generatable by a diffusion model by devising the subband coefficients packing scheme to layout the representation in a low-resolution grid. Further, we derive the subband adaptive training strategy to train our model to effectively learn to generate coarse and detail wavelet coefficients. Last, we extend our framework to be controlled by additional input conditions to enable it to generate shapes from assorted modalities, e.g., single/multi-view images, point clouds, and low-resolution voxels. In our extensive set of experiments, we demonstrate various applications, such as unconditional generation, shape completion, and conditional generation on a wide range of modalities. Our approach not only surpasses the state of the art in delivering high-quality results but also efficiently generates shapes within a few seconds, often achieving this in just 2 seconds for most conditions.
Single-view Image Conditioned Generation
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
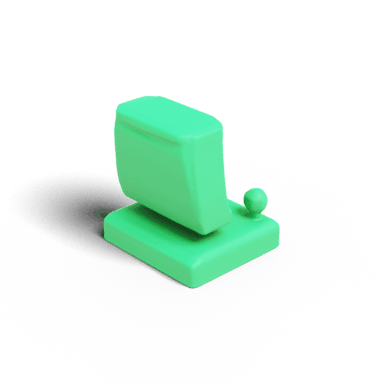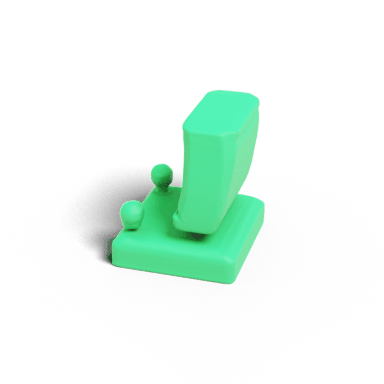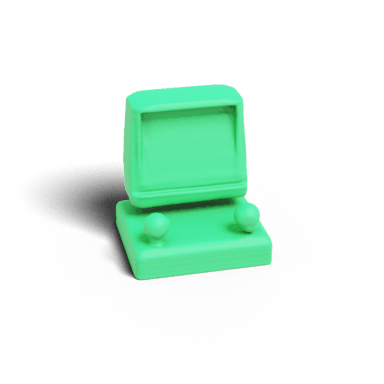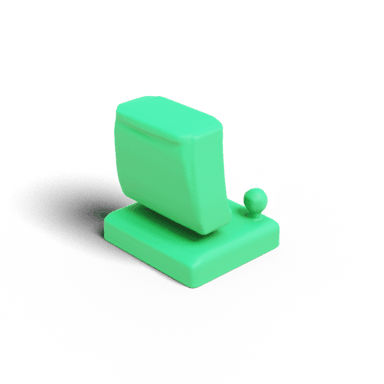 |
 |
 |
 |
 |
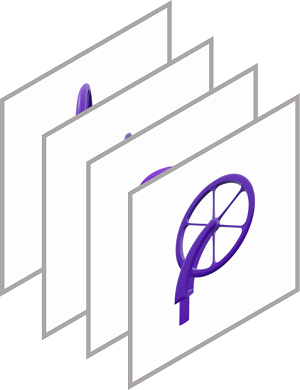
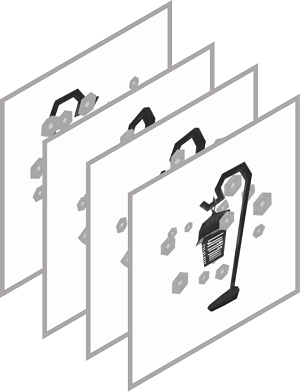
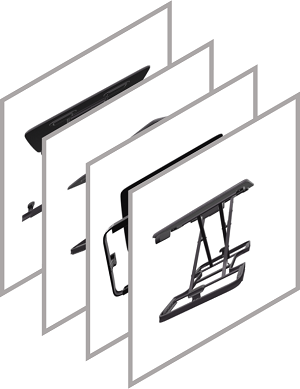
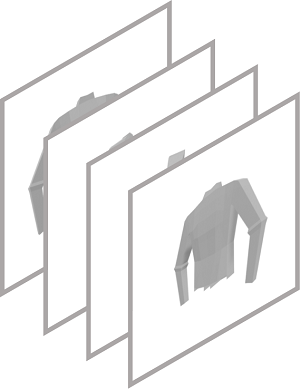
Multi-view Images Conditioned Generation
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Point Cloud Conditioned Generation
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
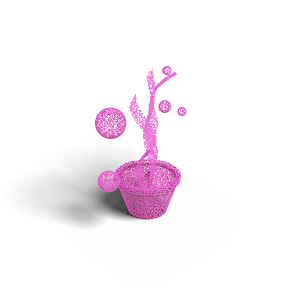 |
 |
Voxels Conditioned Generation (16^3)
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
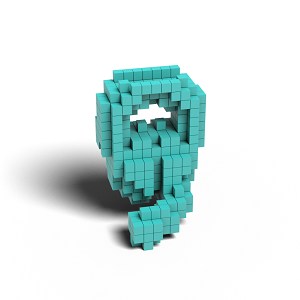 |
 |
 |
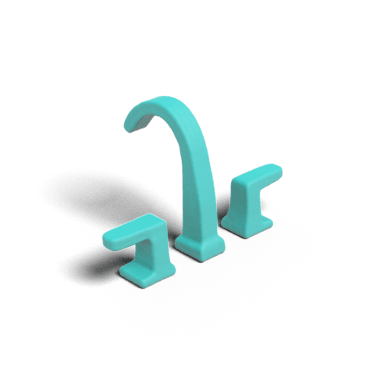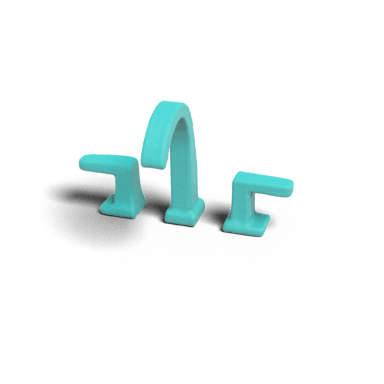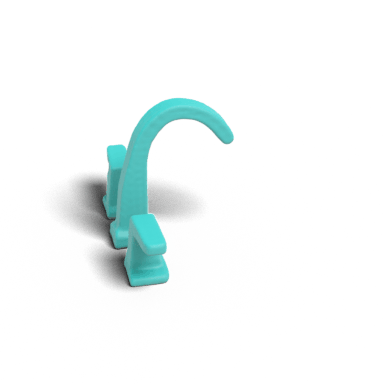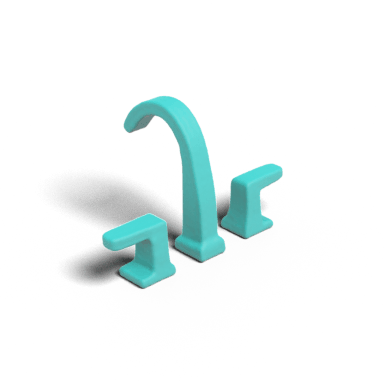 |
 |
 |
Voxels Conditioned Generation (32^3)
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Shape Completion
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Paper
 |
Make-A-Shape: a Ten-Million-scale 3D Shape Model [Paper] |
Get in touch
Something pique your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities.
Contact us