Revolutionizing Water Management
Applying Reinforcement Learning for Pump Optimization in Water Distribution Networks
In our previous post, we discussed a pioneering collaboration between Autodesk Research and Innovyze to successfully integrate Reinforcement Learning (RL) techniques into Innovyze’s products to optimize water distribution networks. This integration is a testament to research advancements and strategic implementation that resulted in a novel product feature for a vital resource. We elaborated on how the team navigated the transition using a hybrid RL approach, blending the established query-based model with the new RL solution to ensure seamless integration thorough validation and risk mitigation.
Evaluation & Result
The environment used to train our RL-agent is shown below (Fig. 1) which has more than 6 pump/valve stations, 6 reservoirs, and 18 demands. It is the Machine-Learning based simulation we built for this complex structure of water distribution network.
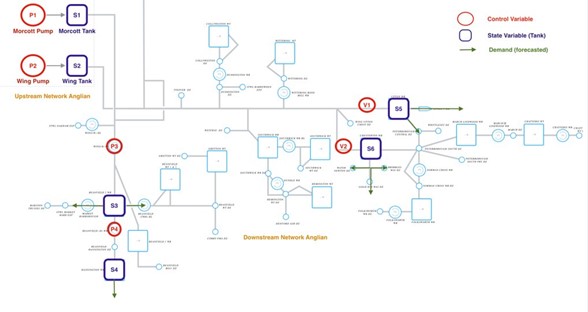
Fig 1. Water Distribution Network for Anglian
We have also prepared the generalized version of the above complex structure representing all the reservoirs in a single tank (Total Network Volume) and combining all the demands in the single (Total Network Outlet). The control setpoints are the Total Inlet Flow (Morcott Inlet + Wing Inlet) representing the main source of the inlet for the plant. We performed a set of experiments for this simpler version of network shown in Fig. 2 and considered three objectives while training the RL agent:
- Constraint Violation: Keep level under upper/lower constraints.
- Energy Savings: Energy optimization with respect to tariff structure.
- Toggle count: Keep count of change in control setpoints under threshold.
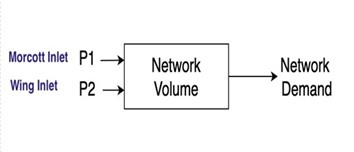
Fig 2. Generalized version of Anglian Network
After training our RL-agent, we prepared a list of experiments so that we can evaluate its performance in energy saving and constrain maintains perspective by introducing various initial conditions and abnormal demand patterns.
We generated the following results using PPO agent from RLlib with custom Gym environment and prepared the reward function so that agent can be reinforced correctly for the three objectives in the right manner.
We also conducted a thorough cost-savings analysis for every day of the year 2020. The following time-series and bar chart (Fig. 3) represents the daily and monthly aggregated cost savings for 2020. Yearly average saving percentage comes out ~4.5% and fairly distributed over months.
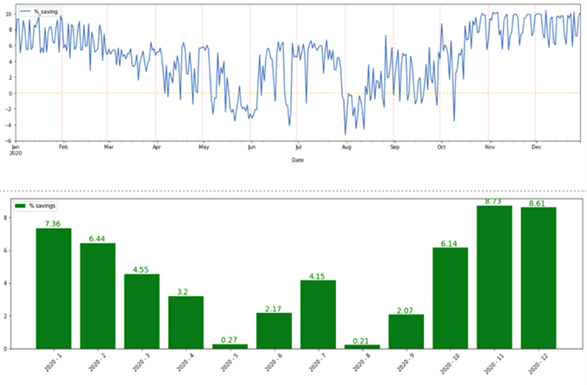
Fig 3. Daily and monthly savings results
Apply RL to Product with Trust
We adopted a hybrid approach to ensure client trust and a smooth transition, gradually incorporating RL into our pump optimization strategies while maintaining the reliability of a query-based model. This incremental transition allows us to leverage the benefits of RL without sacrificing the proven performance of the existing query-based model.
In this hybrid model, the query-based model serves as a reliable baseline for pump optimization, providing accurate predictions and recommendations based on historical data and predefined rules. Simultaneously, RL generates the setpoints for the subset of the next 24-hour period based on different criteria and combines with the results from the query-based model.
By hybrid-RL models, we ensure a smooth and controlled transition while minimizing any potential risks or disruptions. This approach allows us to maintain client trust by providing reliable and explainable results while incrementally harnessing the power of RL to optimize pump operations in water distribution networks. Through this hybrid model, we strike a balance between stability and innovation, delivering effective and trustworthy solutions to our clients. In the end, hybrid control setpoints will be compared against the baseline schedule and the best schedules will be selected to recommend in real-time.
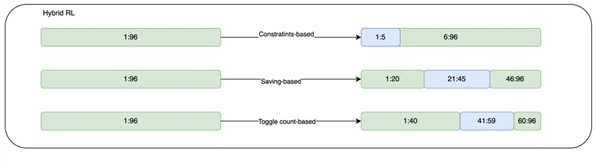
Fig 4. The slot selection strategy for Hybrid-RL
Conclusion
Our approach combines an RL-based method with a query-based warm start approach to deliver real-time optimal control setpoints for water distribution. By utilizing initial water levels, tariff structure, and demand predictions as inputs, our approach effectively identifies optimal setpoints that achieve cost savings while adhering to operational constraints. In the deployment phase, we gradually introduce RL-based setpoints to enhance the robustness of the final control strategy, incorporating the current operational routine and accounting for potential simulation errors.
The integration of RL into our approach brings several improvements over traditional methods like Genetic Algorithm (GA). RL excels in dynamically adapting to changing conditions and real-time decision-making, allowing for optimized control setpoints in response to varying demand patterns, energy costs, and network conditions. Furthermore, RL’s sample efficiency enables quicker convergence to near-optimal solutions, enhancing the overall efficiency and performance of water distribution systems. By leveraging the strengths of both the query-based warm start and RL, we provide clients with reliable and cost-effective solutions for optimal pump control in water distribution networks, ensuring efficient operation while maintaining necessary constraints.
Harsh Patel is a Principal Machine Learning Engineer, AEC
George Zhou is a Manager, Machine Learning, AEC
Ashley Wang is a Senior Machine Learning Engineer, AEC
Rodger Luo is a Principal AI Research Scientist, AI Lab
Get in touch
Have we piqued your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities
Contact us