From Prediction to Prescription: Why Causality Matters for Responsible AI (Part 1)
As autonomous systems increasingly make high-stakes decisions, including coding agents, credit approvals, and medical diagnosis, correlation-based analysis alone is not adequate. Responsible AI requires systems that are explainable, can withstand stress tests, and be held accountable for their decisions.
This is where causality supersedes a purely correlation-based analysis. Causality provides conceptual and mathematical tools that allow models to move beyond pattern recognition and towards understanding why outcomes occur. Instead of asking, “What is correlated?”, Causal AI asks the far more powerful question, “What will happen if we intervene?” This enables us to narrow the subset of related features or covariates to the causal features that directly influence the outcome.
Causality also plays a critical role in analyzing data and deriving actionable insights across multiple domains at Autodesk Research. For time series data collected from sensors installed in buildings, causal analysis helps identify the underlying factors that influence confidence intervals for forecasting. In heavily regulated industries such as construction and manufacturing that encompass worker safety and environmental impact, it enables a deeper understanding of the drivers impacting project planning. Similarly, in foundation models with transformer architecture, next-token prediction is inherently causally dependent on the sequence of preceding tokens.
The purpose of this two-part blog series is to outline the rigorous steps involved in designing a robust causal inference pipeline, including refutation methods and stress testing. This strengthens confidence in causal findings through empirical validation. Insights that consistently withstand such scrutiny foster greater trust and reliability, making them suitable for deployment in real-world applications. Furthermore, when results are transparent and explainable, stakeholders are better equipped to make informed interventions that can positively influence outcomes.
This first part will delve into the pillars of Responsible AI, historical motivations for causal research, and an overview of key concepts. The second part will cover a case study on estimating causal effects using a publicly available NASA Kaggle software defect dataset.
Why Causality is Central to Responsible AI
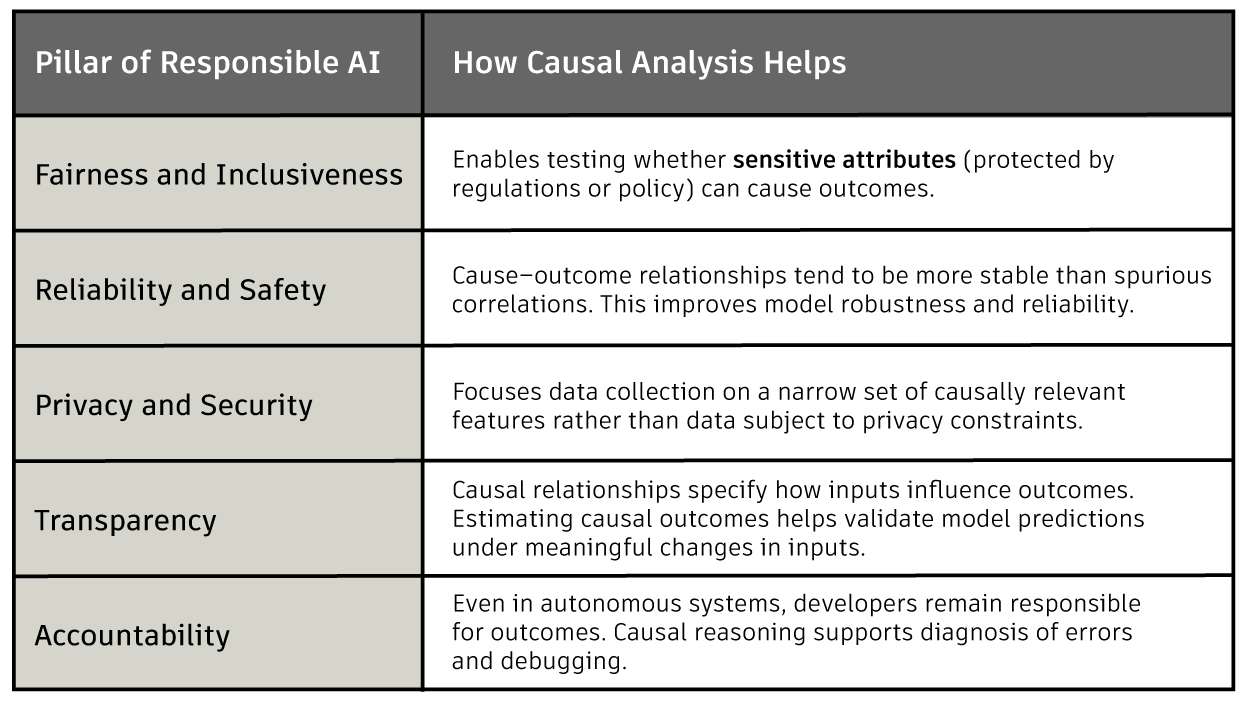
The Responsible AI Pillars (RAI) provide a shared framework for developing and deploying AI systems that positively impact individuals and society. They help teams move beyond technical performance to consider real-world consequences for their models. They also guide better governance and clearer ownership across the model development lifecycle.
What Does it Mean to Prove Causality?
An important question that consistently comes up in causal analysis is “How do we prove causality?” This question has shaped decades of scientific thinking about how causal assumptions and experimental evidence interact. Medical research, which had to identify the cause-outcome link between medicine and recovery, helped formalize a framework to answer this question, notably the Bradford Hill criteria proposed in 1965.
Sir Austin Bradford Hill was a British statistician and epidemiologist who played a key role in shaping modern causal research. One of his most influential contributions was promoting the use of randomized controlled trials, or RCTs, to establish cause and effect relationships. In an RCT, participants are randomly assigned to a treatment group or a control group. This random assignment helps ensure that other factors, such as lifestyle, income, or underlying health, are evenly distributed between the groups.
These other factors are called confounders. Confounders influence both the cause and the outcome. If they are not accounted for, they can create misleading conclusions about what truly caused the outcome. Randomization breaks the link between confounders and treatment assignments, allowing researchers to attribute differences in outcomes more confidently to the treatment itself. This innovation transformed medicine by making causal claims more reliable and reducing bias that affected earlier studies.
However, randomized trials are not always possible or ethical. Some questions cannot be tested through experiments, especially when there is a risk of harm. Hill faced this challenge when working with Richard Doll to investigate the link between cigarette smoking and lung cancer. Their findings were based on observational data rather than randomized trials, and their conclusions were initially met with skepticism. This experience led Hill to consider how scientists can responsibly argue for causation when controlled experiments are not feasible.
In 1965, he introduced a set of guiding principles to support causal reasoning in observational research. These principles include the strength of the association, consistency across studies, plausibility of the explanation, and temporality, which means that the cause must occur before the outcome. These criteria are not a rigid checklist but a framework to guide scientific judgment. Among them, temporality is fundamental. For X to cause Y, X must occur before Y.
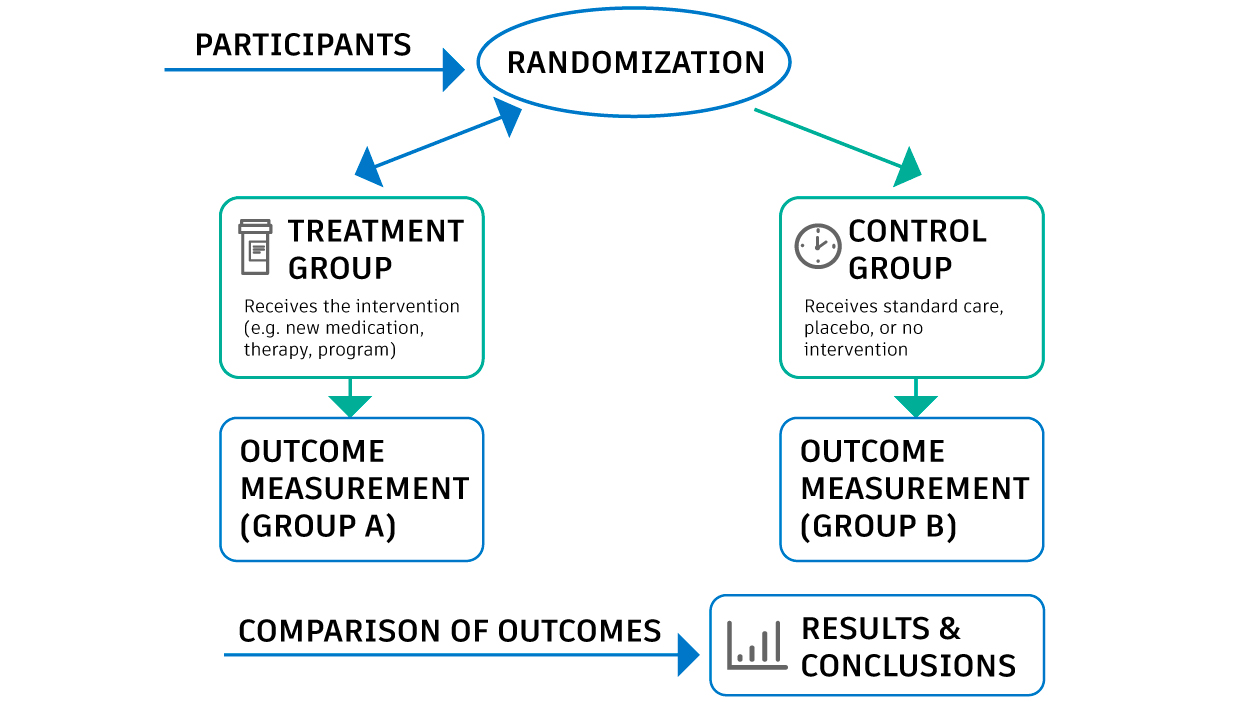
Fig.1 Diagram illustrating a randomized controlled trial (RCT). A placebo is a fake medicine/treatment given to the control group that does not contain an active medical ingredient, for example a sugar pill.
The Building Blocks of Causal Analysis
Causal analysis relies on several foundational concepts that shape how problems are framed and solved.
- Confounders are features that influence both the cause and the outcome. If they are not properly accounted for, causal estimates become biased.
- A causal hypothesis is a concrete, testable claim that changing one feature will cause a change in another. Unlike correlational hypotheses, causal hypotheses commit to a direction of influence; that a causal feature leads to the outcome and not vice versa.
- Causal reasoning builds on these hypotheses to answer intervention-focused questions. It examines the consequences of actively intervening on a causal feature and how such changes would influence outcomes.
- Causal discovery focuses on learning plausible causal structures directly from data, often when prior domain knowledge is limited. These methods use patterns such as conditional independence or temporal ordering to suggest candidate causal graphs.
- Counterfactuals test whether the prediction of a model would change if a causal feature were altered while all other factors remained constant. It helps answer the question, “What would have happened had we intervened differently?” In settings where causal features are binary, such as a randomized controlled clinical trial with a binary treatment flag, random allocation allows outcomes in the control group to serve as a counterfactual outcome for the treatment group.
- Finally, causal inference is the process of estimating the magnitude and direction of causal outcomes. Modern open-source causal inference tools recommend the following steps: Causal hypotheses to be made explicit through a causal graph, estimates of how much one unit of change in the cause impacts the outcome and stress tests or refutations of these estimates.
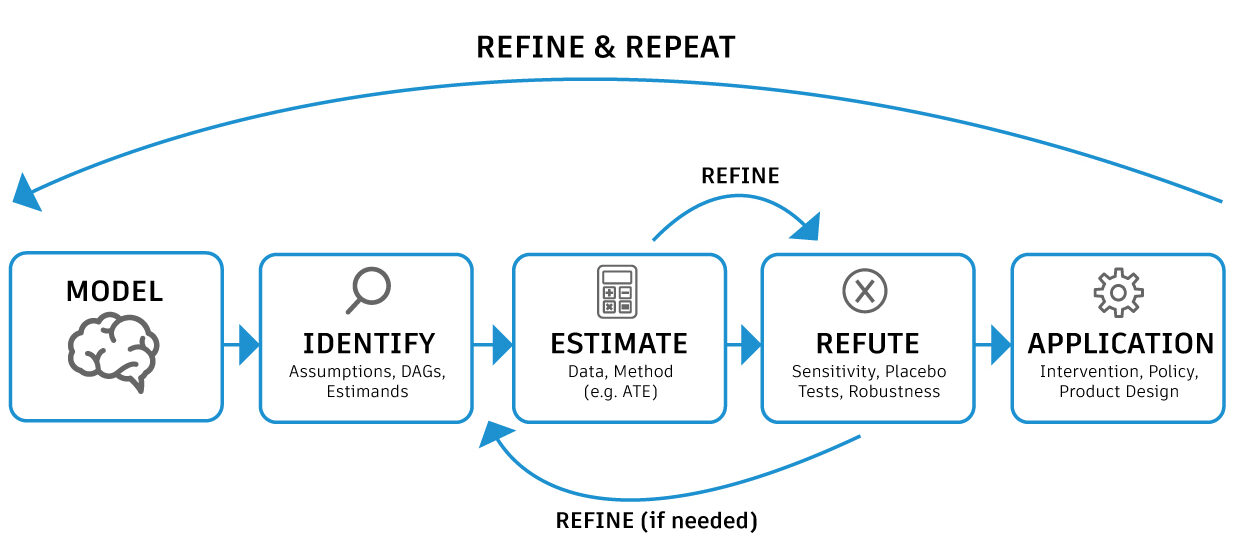
Fig 2. A causal inference pipeline: Modelling involves creating an acyclic causal graph with edges connecting the cause to the effect. ATE (Average Treatment Effect) is the average difference in outcomes for the treatment versus the control group.
Conclusion
Causality equips researchers and data scientists with a rigorous framework to distinguish true drivers of outcomes from spurious correlations. In doing so, it provides the foundation upon which the pillars of Responsible AI rest. In Part 2 of this series, we apply these principles in a hands-on case study, estimating and stress-testing causal effects using a public software defect dataset.
Get in touch
Have we piqued your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities
Contact us