Safer by Design: Benchmarks for Generative AI
AI is changing how designers work, from conceptual ideation to engineering validation. But with the flood of new models, how can we tell if an AI assistant is actually useful, or even safe, in real-world design contexts?
Autodesk Research collaborated with MIT, UC Berkeley, and Carnegie Mellon University to create new benchmarks for evaluating LLMs on engineering design tasks. These benchmarks test models on three key challenges: interpreting complex design requirements, making nuanced material selections, and assessing potential risks that could lead to consumer product recalls. Together, they offer a structured way to probe the capabilities and biases of today’s models, and the promise (and limits) of tomorrow’s design copilots.
AI Model Evaluation: A Foundation from the Machine Learning (ML) Community
Before we can understand how LLMs might support engineering tasks, we need to understand how they’re typically evaluated. In the broader ML community, benchmark-driven evaluation is the norm. Models are routinely tested on standardized datasets to assess their ability to perform specific tasks, whether it’s answering questions (SQuAD, WikiQA), understanding scientific literature (QASPER, ScienceQA), or navigating complex, real-world prompts (ZeroScrolls, OpenAI’s HealthBench).
These benchmarks serve a dual purpose: they offer a snapshot of current model performance and enable meaningful comparisons across models and even against human baselines. This structure has helped drive innovation, reveal model limitations, and encourage transparency across the AI research ecosystem.
However, while these benchmarks have transformed how we evaluate language models in domains like healthcare and software engineering, they rarely extend into the world of product design and engineering. The tasks and reasoning in those fields, such as interpreting ambiguous requirement documents, understanding trade-offs in material properties, or anticipating failure risks, are rarely captured in traditional NLP datasets.
And that’s where our work begins.
Why Design Needs Its Own Benchmarks
While traditional benchmarks have propelled progress in many areas of machine learning, they fall short when it comes to evaluating how well models understand and support design workflows. Product design is a domain rich with tacit knowledge, open-ended reasoning, and constraints that don’t fit neatly into typical Q&A formats. Questions like “Is this material appropriate for high-cycle fatigue?” or “Does this design meet both safety and manufacturability standards?” require deep contextual understanding, domain expertise, and reasoning over trade-offs.
To address this gap, we developed a suite of multi-modal benchmarks tailored to the challenges of engineering and design. Each benchmark is rooted in real-world tasks that engineers and designers face and aims to uncover both the strengths and limitations of LLMs.
So far, we focused on three representative areas:
- Engineering Documentation: Testing comprehension of dense technical specification documents.
- Material Selection: Evaluating model behavior when choosing materials under uncertainty.
- Product Recalls: Exploring how models interpret and learn from past product failures.
These benchmarks form a foundation for systematic, repeatable evaluations that go beyond generic intelligence and dig into what really matters in engineering: accuracy, reliability, and domain relevance.
DesignQA: Testing LLMs on Engineering Requirements
One of the most foundational tasks in engineering design is communicating design requirements, and outlining the constraints, specifications, and rules governing a project. It’s where innovation meets reality. Yet, interpreting these documents isn’t easy, even for experienced engineers.
We built DesignQA to test this question: Can LLMs make sense of a real engineering rulebook? Using the 2024 Formula SAE racing rules, spanning material specs, safety limits, and dimensional tolerances, we developed a dataset of 1,451 questions that span a wide spectrum:
- Basic extraction: “List all rules about the suspension.”
- Rule comprehension: “What is the name of the component highlighted in this screenshot?”
- Functional reasoning: “Do the simulation results for the motor mount indicate any rule violations?”
The goal was to probe the model’s ability to engage with real engineering content. The benchmark goes beyond text comprehension, and evaluates diagram interpretation, multi-step reasoning, and compliance checking, tasks that mirror the kinds of questions designers ask every day.
Early results show that while LLMs can retrieve explicit information reasonably well, their performance drops when questions require synthesis across multiple rules or involve implicit constraints. DesignQA reveals the boundaries of what models currently understand and helps define what future models must learn to support real-world engineering.

Overview of the three different segments (Rule Extraction, Rule Comprehension, and Rule Compliance) and six subsets (Retrieval, Compilation, Definition, Presence, Dimension, and Functional Performance) in DesignQA. Prompts and images shown above are condensed versions of the actual prompts and images used. The bottom right table shows the metrics and the number of questions for each subset of the benchmark
MSEval: Uncovering Bias in Material Recommendations
Choosing the right material is a cornerstone of engineering design. It’s a decision that balances functionality, manufacturability, cost, sustainability, and safety, and often has no single correct answer. A part might be made of aluminum in one scenario, stainless steel in another, and a composite in a third, depending on the performance requirements and trade-offs. This complexity can expose how LLMs reason, and their biases.
To expose these biases, we built MSEval. We collected over 10,000 survey responses from design professionals on material choices for a diverse set of design scenarios. These answers were then compared against LLM outputs for the same prompts.
This research showed that while LLMs were often able to suggest technically feasible materials, their selections showed a noticeable bias: a strong preference for “exotic” or high-performance materials like titanium or composites, even when those materials were impractical for cost-sensitive or mass-manufactured designs.
These findings highlight a key risk: models may default to optimal-sounding answers that are not contextually appropriate. Without grounding in real-world constraints (like supply chain availability, manufacturing techniques, or cost) LLMs may unintentionally mislead designers exploring material options.
The benchmark enables structured evaluation of this behavior and helps us understand where models align with expert judgment, and where they don’t. As AI copilots become more integrated into design tools, such insights are critical for guiding model improvement, user training, and responsible deployment.
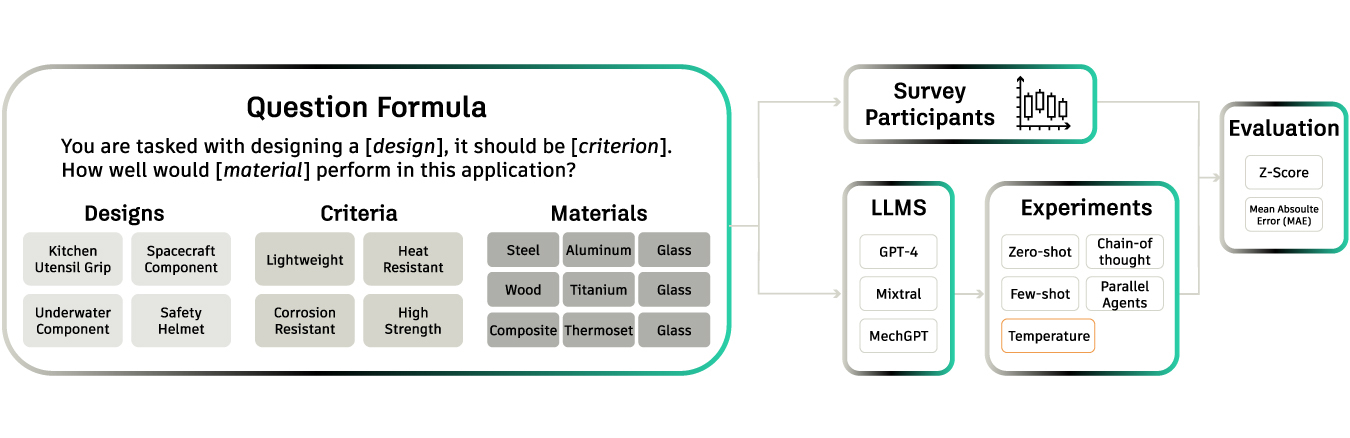
Overview of the method used to create the corpus of questions submitted to survey participants and to the LLMs, the experiments used to evaluate the LLMs, and the evaluation metrics used to compare the LLM results to the survey responses
RECALL-MM: Predicting Risk from Past Failures
Product recalls contain a wealth of insights into design-related risks, yet integrating these findings into early-stage design is time consuming and difficult. To address this, we created RECALL-MM, a curated multimodal dataset built from the U.S. Consumer Product Safety Commission (CPSC) recalls database. The dataset combines product names, recall descriptions, and images to enable data-driven risk assessment.
In the paper, we demonstrate the utility of RECALLS-MM through three case studies:
- Pattern discovery across similar recalled products.
- Proactive design assessment, using recall proximity to guide safer decision-making.
- LLM-based hazard prediction from product images alone, showing strong alignment with historical risks, but also revealing current limitations in modeling hazards.
RECALL-MM bridges the gap between historical data and forward-looking design tools, offering a scalable approach to building safer products.
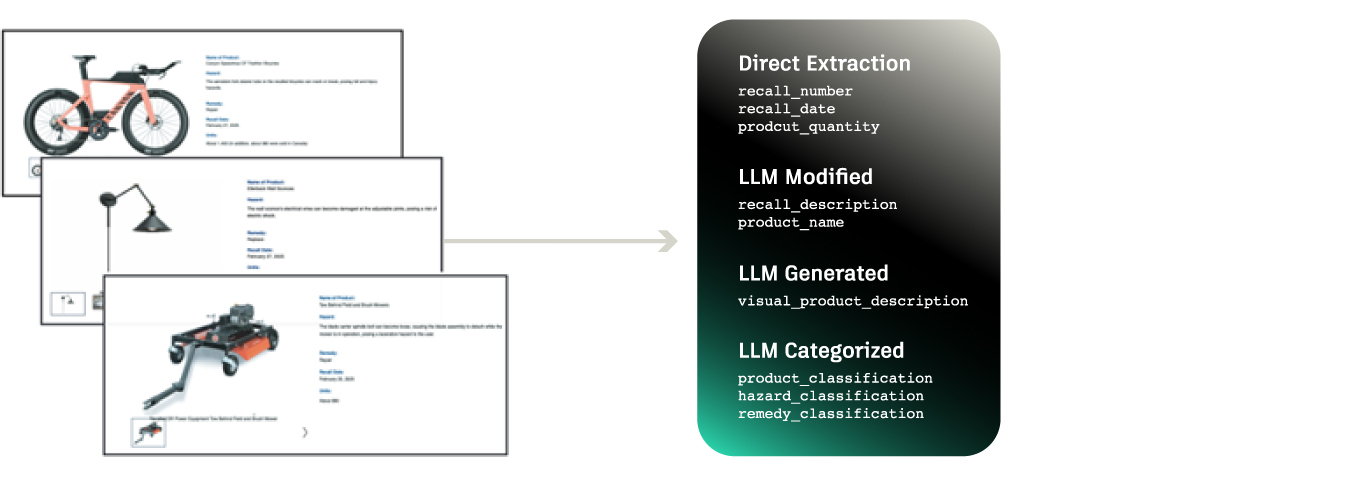
Example CPSC entries, and the nine data fields present in the dataset
Looking Ahead: Designing the Next Generation of Benchmarks
This is a first step. By evaluating how models interpret design requirements, recommend materials, and anticipate product risks, we’ve started to understand what AI can and can’t do for engineering design today.
Good benchmarks are essential to responsible AI in design, but developing them is labor-intensive. As AI systems grow more powerful and more deeply integrated into design tools, we need reliable ways to assess their strengths, expose their limitations, and guide their responsible use.
Just as benchmarks have shaped progress in software development and natural language understanding, the future of design AI demands new benchmarks that go beyond text and images to evaluate how models interact with 3D geometry, make complex architectural or mechanical decisions, or adapt designs in response to real-world constraints like supply chain disruptions. What is hindering progress in this space is a lack of public data: 3D geometry is much more sparse online than text and images. Synthetic data generation methods will have to fill in the gap.
Building these next-generation benchmarks isn’t just a research project, it’s a challenge for the broader design and engineering community.
Get in touch
Have we piqued your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities
Contact us