Bridging Design, Human Sciences, and Technology with AI Art
Traditional building design has typically focused on cost efficiency and program optimization, thus ensuring that new construction is financially viable and functional. However, this paradigm is evolving due to new advances in neuroscience, which have revealed the profound impact that our surroundings have on our mental and physical health. Using variables such as natural lighting, views to the outside, materials and textures, and acoustics—all of which influence our productivity, stress levels, mood, and social interactions—designers can devise buildings that support human well-being while meeting traditional performance requirements.
As Autodesk customers use our design and make platform to create better buildings, Autodesk Research is examining this trend and contemplating its future directions. We launched the Encoding Experience project to explore the impact the built environment has on human well-being. This interdisciplinary project, which sits at the intersection of design, technology, and human sciences, kicked off with a series of dinner events held in Boston and San Francisco. There, we invited various experts and practitioners from diverse fields such as architecture, public health, engineering, neuroscience, and AI, to get insights into the state of the field and the practice, build a community, and drive future research.
To add an element of fun and playfulness to the dinners, I was approached by the organizers to develop an interactive experience for the guests. The following is a glimpse into the process, the technology used, and the results of this endeavor.

The generative AI system running at the Boston (left) and San Francisco (right) Encoding Experience dinners.
The Challenge
I received an unexpected, informal request from our team leads and event planners for an interactive component to engage the guests during the cocktail hour of the dinners. We discussed various ideas and hardware components we could incorporate into the experience. The biggest challenge was the timeline: with less than four weeks before the first event to design and execute the idea, this was certainly no small feat. Also, I had only worked with hardware once before in From Steps to Stories (The Bentway Project), so the timeline indeed felt short! Regardless, I accepted the challenge.
The Inspiration
As I brainstormed, I promptly decided to create a visually compelling experience, as many of our invited guests have backgrounds in design and architecture. I was reminded of ReCollection, an art installation exhibited at the SIGGRAPH 2023 Art Gallery that my colleague Rodger Luo had worked on. I had also recently visited the ARTECHOUSE in Washington D.C. and was inspired by the interactive experiences I encountered there. Additionally, as part of our research in media and entertainment, I had been exploring AI image generation tools.
These experiences sparked the idea to create an art installation that generates images of built-environments showcasing human-centered design principles for architecture, such as natural light, views to the outside, and use of nature-colored tones and textures. To make the system interactive, a camera would be pointed at the dinner room, taking photographs which would guide the composition of the generated image. My vision was for the guests to play with their bodies and other random props to influence the generated art.
The Technology
Typically, when an image is used to control the composition or shape of an AI generated image, it is a specialized type of image that will, in a sense, suggest or influence the AI to generate an image in a prescribed way, thus providing the broad strokes for the final composition. The more standard types of control images are depth or edge images, but others exist as well.
We had a couple of depth cameras in the lab, so in my initial designs, the cameras would shoot depth images directly. However, these cameras were old and no longer supported, and the images they produced did not meet the visual quality standards I was aiming for. After some experimentation, I quickly discovered I could use generative AI to produce a depth image from a regular photograph, so the depth cameras were set aside.
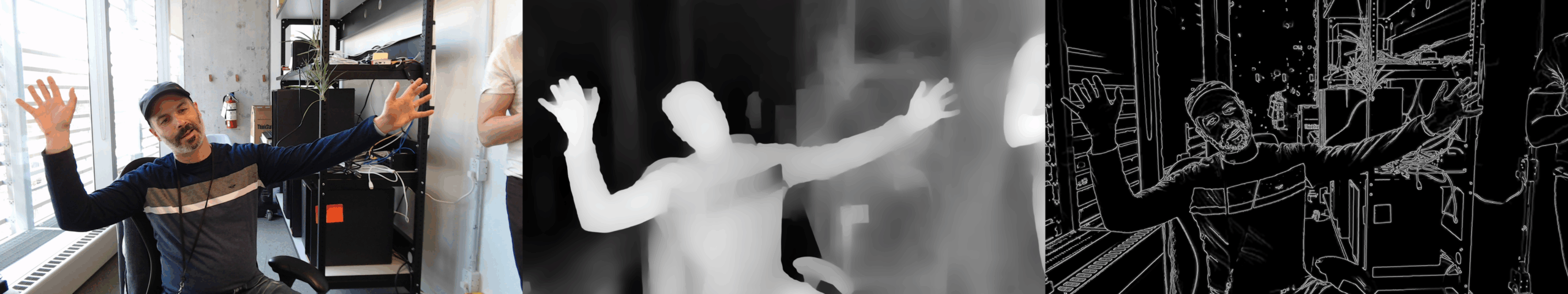
At the beginning, I also figured the entire system could be run on one machine—hopefully a laptop—with a powerful GPU that we would transport to the dinner locations. Then I discovered that the image-generating platform I wanted to use, ComfyUI, was already written in a client-server model, where the server’s role was to generate the images for the client user interface (UI). It would be easy to replace the UI with my own, so the laptop running the system would not need a powerful GPU after all.
Thus, I decided to build the entire system as a web application, running on the browser, that accesses the user’s camera, eliminating the need for specialized hardware, which also simplified our installation logistics.
After much experimentation, I developed a ComfyUI workflow that included the generation of a depth image from a photograph and provided the right level of control. I created prompts for eight different scenes which would be generated at random: a house, a building, the interior lobby of a building, an office space, a library, a ski resort, a beach house, and a living room with a woman reading a book while sipping tea. In the prompts I provided design cues that are known to support human well-being, such as “abundant views to the outside,” “lots of natural light,” and “nature-inspired colors and textures.” Finally, the workflow also accepted a variable to change the rendering style of the output image, and five different styles could be chosen at random.
With the basic workflow finalized, the last step was to replace the client-side UI with my own, which would place calls to the ComfyUI server for image generation. This was the first time I wrote a web application, so I had to quickly ramp up my skills. The biggest challenge was figuring out how to send and receive commands and images from my app to the webserver. Luckily, as ComfyUI is an open-source project, I was able to look through the code to understand how things were put together.

Some (very) last minute adjustments!
The Finer Details
For those curious about the nitty-gritty details, the system is a React application. It uses the Media Stream APIs from the browser to access the webcam stream and grab a frame at the specified moment. That image frame is sent to the server using ComfyUI’s own APIs, much like the LoadImage node uploads images. Then, a prompt, style, and seed are selected at random to queue the workflow on the server.
The workflow uses the FLUX.1 [dev] model with the FLUX.1 Depth [dev] LoRa for depth control. The latter is also combined with a second LoRa for style. All the style LoRas, obtained from CIVITAI, were developed to enhance architectural renderings.
The Results
We debuted our generative AI system at the Boston Encoding Experience event. Our hope was for the guests to play with the system during the cocktail hour before the dinner. However, we quickly discovered people were more interested in connecting and getting to know one another, as many were meeting for the first time. Nonetheless, there were lots of positive comments about the work and a few guests were curious enough to ask me for a demo and explanation. Once the dinner started, we let the system run with the camera pointed at some props.

Examples of the eight different prompts in various styles, based on very similar control images. In clockwise order from the top left: beach house, building lobby, building exterior, house, ski lodge, office space, living room, and library.
For the San Francisco event, I extended the workflow to add a short video based on the generated image (using a simple LTXV image to video workflow), but I was not able to get the system timing correct before the dinner, so we ran the original version. We again let the system run with the camera pointed at some interesting props. Due to the arrangement of the space, the system appeared as an ever-changing art piece in the room, which provided some extra liveliness to the event.
A time lapse video of the collection of images generated at the San Francisco event and the source photograph, courtesy of Kean Walmsley.
In hindsight, the system was a bit too slow for folks to spend time interacting much with it. I was rendering 1080p HD frames, which took about 30 seconds per generated image cycle. Had I had more development time, I could have tested using 720p frames instead, or even something smaller with an up-sampling step to make the image generation cycles faster. However, we also noticed that the limited time window for interacting with the system, coupled with the limited control of the final output, made the system for fun: at each iteration, users become excited to try out new shapes or body positions to find out what the system will generate next.
How the generative AI system runs in practice
Conclusion
This project was a fascinating journey into the world of interactive art and technology. Despite the tight timeline and technical challenges, the interactive art installation was a success, adding a unique and engaging component to the Encoding Experience dinners. I was also delighted to learn new tools and technologies in a creative endeavor. I am grateful for the opportunity to contribute to such an innovative initiative and look forward to future projects that explore the intersection of design, human sciences, and technology.
Sample output image and video generated during testing before the San Francisco dinner.
Get in touch
Have we piqued your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities
Contact us