AI Alignment in CAD Design: Teaching Machines to Understand Design Intent in AutoConstrain
- Why Design Intent Matters: In parametric CAD, AI-generated constraints need to capture the “design intent” of the sketch — the underlying structural relationships that should be preserved when a sketch is edited.
- What We Did: We adapt post-training techniques from large language models (LLMs) to teach AI how to generate constraints that preserve design intent, making sketches more editable and requiring less manual work.
- What We Found: Our best alignment method fully-constrains 93% of sketches compared to just 9% for the base model, a 10x improvement that professional CAD designers strongly preferred in evaluations.
Last year, Autodesk Research shared how AI could automatically generate sketch constraints in Fusion through the AutoConstrain feature. That work showed the power of machine learning to reduce tedious manual steps and speed up CAD design. In our new research, we take the next step: rather than just generating constraints, we focus on making sure those constraints reflect the designer’s intent. By adapting post-training techniques from large language models (LLM), this work represents the first successful application of LLM alignment methods to parametric design problems.
The Hidden Challenge in AI-Generated Constraints
Designing a mechanical part in CAD software is more than just drawing shapes – it’s also encoding design intent. This intent determines how the part should behave when dimensions change. Consider the plate design shown below. When a designer adjusts the width of the plate, both sides should remain symmetric. When they change the radius of one hole, all the other holes should update to match. These relationships define what the designer intended, and proper constraints ensure they’re preserved automatically.
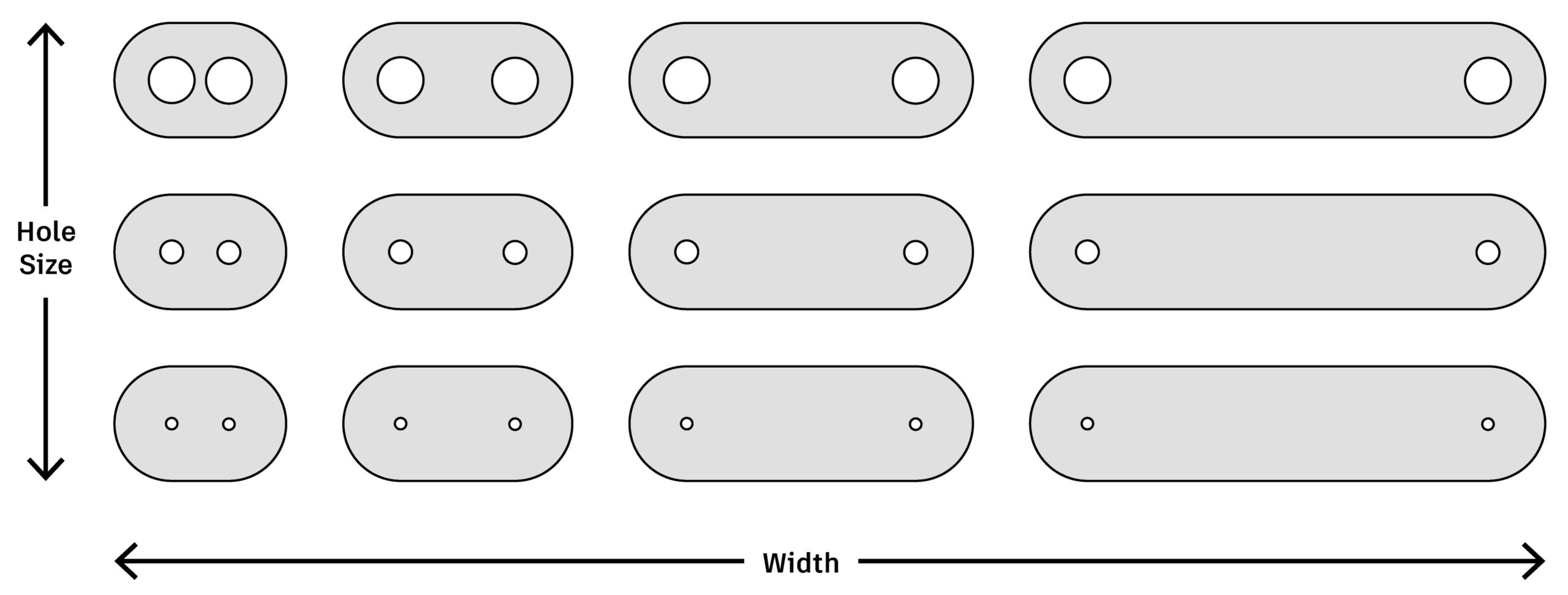
When editing a plate design parametric edits should preserve geometric relationships, such as symmetry and equality of the bracket holes and chamfers.
Traditional CAD software requires designers to manually specify these relationships through constraints – rules that tell the software “keep these two holes the same distance from the center line” or “maintain perpendicularity between these surfaces.” This process is tedious and error-prone, especially for complex designs with dozens or hundreds of geometric elements. Many designers decide to skip this or only partially constrain their sketches: only 8% of sketches are fully constrained in the SketchGraphs dataset, meaning 92% would behave unpredictably when edited.
As we explored in our previous blog post about AutoConstrain, AI has tremendous potential to automate the tedious process of applying constraints to CAD sketches. However, a fundamental challenge remains: how do we ensure AI systems generate constraints that truly preserve design intent? Without proper constraints, AI-generated designs might look correct initially but break down when parameters are adjusted – exactly when you need them to work.
Learning from Language Models: The Alignment Breakthrough
Our research adapts post-training techniques originally developed for large language models like ChatGPT. Just as researchers align language models with human preferences using reinforcement learning from human feedback (RLHF), we developed what we call “design alignment”: using verifiable feedback to align generative models with design intent. In this work, we use Autodesk Fusion’s constraint solver to provide feedback on whether generated constraints create stable, fully constrained sketches. This feedback loop allows the AI to learn what makes good constraints, going beyond simply mimicking training data.
Here’s how it works:
- Model input: The model receives as input the geometry of the sketch without any constraints or dimensions added to it.
- Generate Constraints: The model proposes a set of constraints and dimensions, aiming to fully constrain the sketch. The model is initialized from a pre-trained model that has been trained without alignment.
- Solver Evaluation: The proposed constraints and original geometry are sent to a constraint solver, which checks if the sketch is fully constrained, stable, and does not induce any solve failures.
- Calculate Reward: The solver’s evaluation is converted into a single, numerical reward signal. This reward cleanly communicates to the model whether its output was good or bad.
- Update the Model: The model weights are updated using the reward signal. This adjustment encourages the model to generate constraints that lead to higher rewards in the future. Over many iterations, it learns to produce accurate and stable designs reliably.
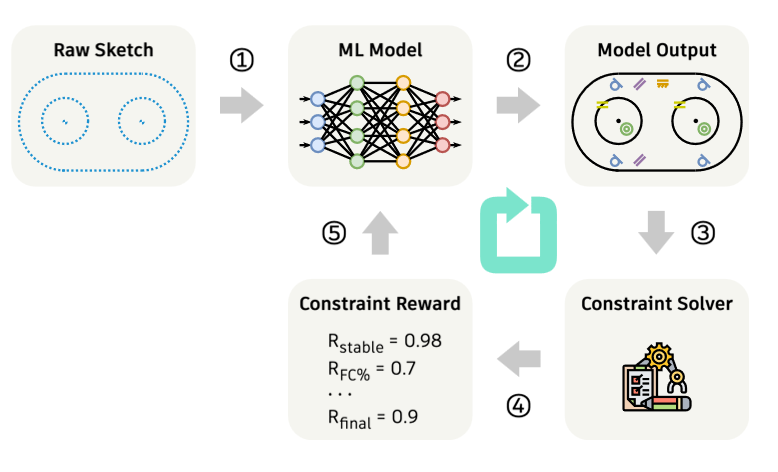
Model generated sketches are scored by the constraint solver, which is used to compute a reward that informs the model training.
Let’s walk through a specific example of a two-hole connector as shown in the figure.
The model is given just the geometry: a rounded body and two circles. The model might correctly apply constraints to define the body, such as making the arcs equal and tangent to the lines. However, it may fail to properly constrain the holes, leaving them able to move along the length of the connector or resize independently. The solver evaluates this design and finds it is only 70% constrained, with several degrees of freedom remaining. This results in a low reward score. Through repeated iterations, the model receives this feedback and learns to improve its constraint strategy.
Through the training process, the model gradually learns to fully constrain sketches, while satisfying other criteria such as geometric stability and validity. As an example, we show animated samples below from an unaligned model (left) and an aligned model (right). The animations show possible variations of the sketch edits. The unaligned model quickly loses symmetry and equality of the holes/chamfers, whereas the aligned model preserves design intent.
Animated visualizations of possible sketch edits from an unaligned model (left) and an aligned model (right)
Results and Methodology
In our ICCV 2025 paper titled “Aligning Constraint Generation with Design Intent in Parametric CAD,” we tested several alignment techniques adapted from language model research, all of which leverage the constraint solver for feedback:
- Direct Preference Optimization (DPO): Learning from pairs of good vs. bad constraint examples
- Expert Iteration (ExIt): Filtering for high-quality outputs and training on them repeatedly
- Reinforcement Learning (RLOO, GRPO): Using a numerical “reward” from the constraint solver for each model output and directly train the model with this value
These methods represent the current approaches for post-training alignment for language models. Testing them on CAD constraint generation allows us to understand which alignment strategies transfer effectively to design problems.
In this work, we used a base model trained on the SketchGraphs dataset and the sketch constraint solver in Autodesk Fusion to score sketch constraints for post-training. We then do supervised fine-tuning (SFT) using only fully constrained sketches and apply alignment techniques on top of the SFT model. Our best method (RLOO) achieved 93% fully constrained sketches compared to just 34% with the SFT model and only 8.9% from the base model.
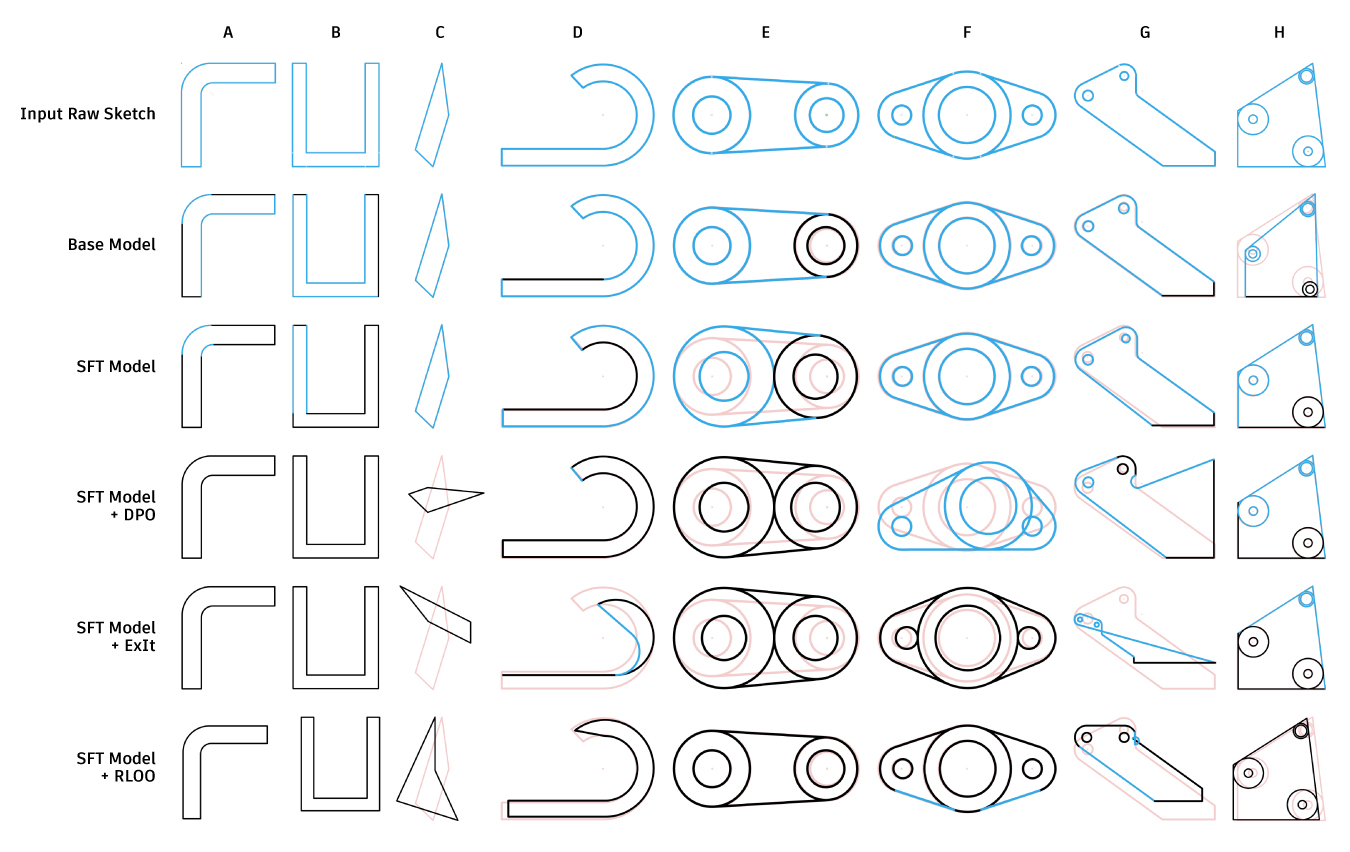
Visual comparison of solved sketches across the baseline and aligned models. Curves are colored black when fully -constrained and blue when not. Overlaid red lines are the original input sketch for reference.
To test whether our alignment methods better capture design intent, we ran a human evaluation with professional CAD designers comparing constraint quality across five model variants: SFT, DPO, ExIt, RLOO, and RLOO with a reward penalty for dimensions. The reward penalty was necessary because the model initially learned to game the system by generating excessive dimensions rather than balanced constraint sets, a phenomenon known as “reward hacking” in machine learning. This mirrors similar challenges faced when aligning language models. We denote this version as “RLOO with penalty.”
In the human evaluation, five professional CAD designers compared 30 sketches of varying complexity in a pairwise forced-choice study. In total this yielded 1500 pairwise evaluations, with the aligned models (DPO, RLOO with penalty, ExIt) being preferred 74.22% of the time over the unaligned SFT model. The best performing model, ExIt, was preferred 83.33% of the time compared to the SFT baseline model. These results validate that the alignment techniques not only improve quantitative metrics but also produce outputs that professional designers judge as better capturing design intent, a key measure of success.

Designers preferred our aligned models over the unaligned model (SFT) with Expert Iteration and RLOO with penalty showing the strongest performance in preserving design intent.
Conclusion
This research marks an important step toward AI design tools that understand and preserve design intent. Our aligned models can now produce sketches that behave predictably when edited, a core requirement in parametric modeling that previously required extensive manual constraint cleanup.
Beyond constraint generation, this work demonstrates that alignment techniques from natural language processing can successfully transfer to engineering design problems, establishing a new paradigm for training AI systems that understand and preserve human design intent.
Get in touch
Have we piqued your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities
Contact us